
RabbitMQ
Depuis plusieurs années maintenant, le développement de solution en temps réel explose et jouis d’une grande popularité.
Cartographie, alertes, réseaux sociaux, messagerie, ne sont que quelques exemples d’applications de ces solutions.
Pourtant, une partie de ces applications ne sont pas en temps réel, mais asynchrones.
La différence réside dans le traitement.
Les applications asynchrones utilisent des processus non bloquants pour le processus principal.
Les “vraies” applications en temps réel utilisent principalement les websockets, permettant une communication bidirectionnelle client/serveur permanente et persistante, qui permet une mise à jour en continue du processus principal.
Avec l’arrivée des WebSocket en 2011, un nouveau standart web émerge.
Contrairement aux requêtes HTTP traditionnelles, ils permettent d’établir une connexion bidirectionnelle et persistante entre un navigateur et un serveur.
Parmi elles on peut citer : WebRTC, Pusher, SignalR ou encore FireBase.
Aujourd’hui nous allons nous intéresser à RabbitMQ, une plateforme de messagerie open source.
Qu’est ce que c’est ?
RabbitMQ est une plateforme de messagerie open-source qui permet aux applications de communiquer entre elles de manière asynchrone.
Il s’agit d’un système de messagerie distribué qui permet d’envoyer et de recevoir des messages dans un environnement décentralisé, ce qui en fait un outil très utile pour la conception de systèmes évolutifs et résilients.
Comment fonctionne RabbitMQ ?
RabbitMQ est conçu sur le modèle de messagerie basé sur les échanges.
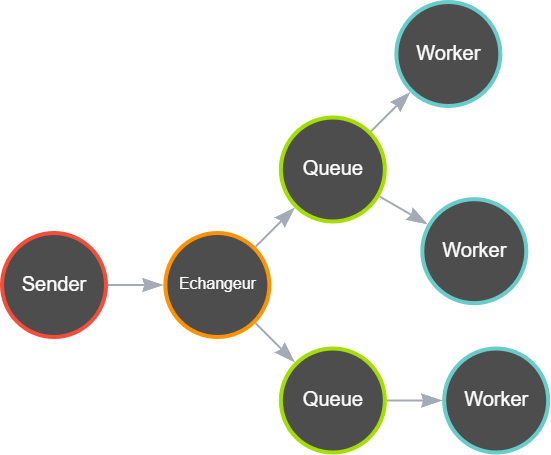
Lorsqu’une application (que nous appellerons Sender) envoie un message à RabbitMQ, elle le fait à un échangeur, qui est un point de distribution pour les messages.
L’échangeur reçoit le message et le transfère à une ou plusieurs files d’attente en fonction des règles de routage définies.
Les Worker peuvent ensuite récupérer les messages de la file d’attente pour les traiter.
Le fonctionnement de RabbitMQ est basé sur un système de protocoles ouverts, tel que AMQP (Advanced Message Queuing Protocol) ou encore WebSocket, qui permet aux applications d’interagir avec RabbitMQ à travers un ensemble d’APIs et de bibliothèques.
Cela permet une prise en charge d’un grand nombre de langages de programmation tels que .NET, Java, Python, Ruby, et bien d’autres.
Quelles différences avec SignalR ?
RabbitMQ et SignalR sont deux outils de communication utilisés dans les applications pour permettre une communication entre les différents composants de l’application.
Cependant, ils présentent des différences significatives en termes de fonctionnalités et d’implémentation.
| Cadre\Outil | SignalR | RabbitMQ |
|---|---|---|
| Architecture | Temps Réel | Asynchrone |
| Utilisation courante | Jeux/Messagerie instantanée | SMS/Email |
| Langages supportés | . Net principalement | .Net/Python/Java/. . . |
| Configuration | Facile, rapide et accessible | Facile, rapide mais un peu moins accessible que SignalR pour optimiser |
| Performances | Très rapide, des ralentissements se font sentir lors de très grand nombres de connexions actives en simultanées | Rapide et efficace, il atteint ses limites lorsque que trop de données doivent être gérées simultanément |
1. L’architecture
RabbitMQ est conçu sur le modèle de messagerie basé sur les échanges, dans lequel les messages sont envoyés à un échangeur, qui les achemine ensuite vers les files d’attente correspondantes.
En revanche, SignalR repose sur un modèle de communication en temps réel qui utilise les WebSockets pour permettre la communication bidirectionnelle entre les clients et le serveur.

2. L’utilisation
RabbitMQ est généralement utilisé pour les systèmes distribués où les applications doivent communiquer entre elles de manière asynchrone.
D’autre part, SignalR est utilisé dans les applications Web pour permettre la communication en temps réel entre les clients et le serveur, comme les applications de chat ou de jeux en ligne.
3. Les langages pris en charge
RabbitMQ prend en charge un grand nombre de langages de programmation populaires, tandis que SignalR est principalement destiné aux applications Web basées sur .NET.
4. La configuration
Les configurations de RabbitMQ et de SignalR sont relativement simples.
Cependant, SignalR requiert un peu mois d’expertise technique pour être déployé de manière optimale.
5. Les performances
RabbitMQ est très rapide et efficace en termes de performances, ce qui en fait un choix judicieux pour les applications qui nécessitent une latence faible et une haute disponibilité.
SignalR est également rapide, mais il peut y avoir des problèmes de performance lors de la communication avec un grand nombre de clients simultanément.
En résumé, RabbitMQ et SignalR sont des outils de communication très utiles pour les applications qui nécessitent une communication asynchrone ou en temps réel, respectivement.
Cependant, ils sont utilisés dans des contextes différents et offrent des fonctionnalités différentes.
RabbitMQ est généralement utilisé pour les systèmes distribués, tandis que SignalR est utilisé pour les applications Web en temps réel.
Le traitement est également différent: tandis que SignalR émets un message vers tous les clients d’un canal, RabbitMQ enverra le message dans une queue et le message attendra d’être lu.
RabbitMQ possède également une notion d’acquittement (automatique ou manuel selon la configuration) qui fait en sorte que, tant que la lecture n’est pas acquitté, le message sera distribué au client suivant.
La configuration de RabbitMQ peut être plus complexe, mais il offre des performances élevées, tandis que SignalR est plus facile à configurer mais peut présenter des problèmes de performance avec un grand nombre de clients.
Et pourquoi pas Kafka ?
Kafka est un système de streaming distribué, contrairement à RabbitMQ qui est un système de messagerie.
Il est conçu pour la gestion de flux de données en temps réel à grande échelle, alors que RabbitMQ est destiné à la communication entre les applications ou services.
Kafka est également plus rapide que RabbitMQ car il est optimisé pour les opérations de streaming à haute performance.
Kafka peut être vu comme un RabbitMQ plus évolué.
On y retrouve d’ailleurs la plupart des fonctionnalités de RabbitMQ.
La différence majeure réside dans le fait que Kafka est capable de traiter des millions de messages à la secondes et permet la relecture de messages déjà consommé et acquitté.
RabbitMQ reste une solution adaptée aux applications nécessitant un système de communication fiable, avec des fonctionnalités de routage et de messageries avancées.
Kafka est plutôt adapté aux cas d’utilisation nécessitant une gestion de flux de données à grande échelle, comme le traitement de données en temps réel et la gestion des données en continu.
Concept de base
Commencons par quelque chose de simple, afin de comprendre le fonctionnement de RabbitMQ
Nous allons créer un client (Sender), une file d’attente (Queue) et un processus de traitement (Worker).
Comme dit précédemment, le Sender enverra sa requête à la Queue en attendant que le Worker soit disponible pour traiter la demande.

Nous utiliserons le CSharp pour ce qui suit.
Pour commencer, assurez vous d’avoir installer ceci: -.NET Core ou .Net Framework 4.5.1 ou supérieur; -Yarn ou NPM via NodeJS (Cet article utilisant yarn, vous devrez adaptez les commandes yarn vers npm en conséquences); -Java; -RabbitMQ Server.
1. Setup
Tout d’abord, vérifiez que le serveur RabbitMQ est démarré.
Ensuite, si . NET est correctement installé, ouvrez un terminal et saisissez la commande:
```PowerShell
dotnet --help
```
Un message d’aide devrait apparaitre.
Générons maintenant 2 projets. Le premier pour le Sender, le second pour le Worker:
```
dotnet new console --name Send
dotnet new console --name Receive
```
Vous devriez voir apparaitre deux dossiers (Send et Receive respectivement), contenant:
```
<ProjectName>
└───bin/
└───obj/
| Program.cs
| <ProjectName>.cs
```
Les dossiers bin et obj contiennent toutes les données générées automatiquement nécessaires à l’éxecution du projet.
Nous ne nous en préoccuperons donc pas.
Accédez aux dossiers Send et Receive et exécuter dans chacun d’eux:
```
dotnet add package RabbitMQ. Client
```
2. Envoi
Pour plus de facilité, nous renommerons les fichiers Program. cs respectivement Send. cs pour notre Sender et Receive. cs pour notre Worker.
Le Sender se connectera a RabbitMQ, enverra un message, puis se déconnectera.
Dans Send.cs:
```CSharp
using System. Text;
using RabbitMQ. Client;
var factory = new ConnectionFactory { HostName = "localhost" };
using var connection = factory. CreateConnection();
using var channel = connection. CreateModel();
```
Ce morceau de code nous permet de créer une connexion avec le serveur.
Il s’occupe de la version du protocole et de l’authentification pour nous.
Ici nous nous connectons à RabbitMQ sur notre machine local, d’où le localhost.
Pour se connecter à un noeud différent de notre machine, il suffit de spécifier le nom de domaine ou l’adresse ip.
Ensuite nous créons un canal, dans lequel l’API va opérer.
Un canal RabbitMQ est liée à la connexion qui lui est donné.
La connexion autogère la forme de communication entre le client et le serveur.
Le canal va utiliser la connexion créée pour construire un modèle de communication entre le client, le point d’échange et la file d’attente.
Après nous être connecté, nous pouvons envoyer nos messages.
Pour ça nous créons une file d’attente dans laquelle nous pourrons publier nos messages.
```CSharp
channel.QueueDeclare(queue: "hello",
durable: true,
exclusive: false,
autoDelete: false,
arguments: null);
var message = "Hello World!";
var body = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchange: string.Empty,
routingKey: "hello",
basicProperties: null,
body: body);
Console.WriteLine($" [x] Sent {message}");
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
```
Déclarer une file d’attente est idempotent, c’est à dire qu’elle aura le même effet à chaque application.
Elle ne sera créée que si elle n’existe pas déjà.
Le message étant un tableau d’octet, il est possible d’y faire passer tout ce que vous souhaitez tant que cela reste sous forme de fichier.
Il y a tout de même une limite de taille pour ce tableau, référencé dans la configuration RabbitMQ.
Auparavant située à 2Go en v3.7.0, cette limite a été abaissée en v3.8.0 par défaut à 128Mo, limite qui a été jugée suffisante pour la majorité des utilisations de RabbitMQ.
Vous pourrez l’augmenter à 512Mo pour conserver un peu de marge, mais tout message supérieur à 530Mo se verra systématiquement rejeté.
Prenez en compte le fait que, bien que la persistance soit assuré par un stockage sur disque, les queues actives sont stockées dans la RAM.
Quand ce code finit de s’exécuter, la connexion et le canal de communication se ferment.
Si c’est la première fois que vous utilisez RabbitMQ et que vous ne voyez pas le message “Sent” sur le terminal du Sender, ou “Hello World” sur le terminal du Worker, vous allez (avec raison) vous demandez ce que vous avez loupé.
Consultez le fichier de log pour en apprendre plus.
Très souvent, il s’agit d’une erreur de disponibilité de stockage.
Pensez à consulter la documentation RabbitMQ avant d’editer rabbitmq.conf en conséquence.
3. Réception
En tant que Worker, nous devons écouter les messages venants de RabbitMQ.
Donc, à la différence du Sender, nous devrons faire en sorte que le Worker reste actif en permanence pour écouter les messages et les recevoir.
Les déclarations sont pratiquement les mêmes que celles de “Send”:
```CSharp
using System. Text;
using RabbitMQ. Client;
using RabbitMQ. Client. Events;
```
Le Setup est le même que le Sender.
On ouvre une connection et un canal, puis on déclare une file que nous allons consommer.
Notez la correspondance de cette file avec celle sur laquelle “Send” publie:
```CSharp
var factory = new ConnectionFactory { HostName = "localhost" };
using var connection = factory.CreateConnection();
using var channel = connection.CreateModel();
channel.QueueDeclare(queue: "hello",
durable: true,
exclusive: false,
autoDelete: false,
arguments: null);
//...
```
Notez que nous déclarons la file d’attente ici également.
Comme nous pourrions démarrer le consommatteur avant le Sender, nous voulons être sûr que la file d’attente existera avant d’essayer de la consommer.
Passons maintenant à la partie lecture depuis la file d’attente.
Puisque le message sera poussé de manière asynchrone, nous devons fournir un callback.
Nous allons donc capturer l’évènement grâce à EventBasicConsumer.Received.
```CSharp
Console.WriteLine(" [*] Waiting for messages.");
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body.ToArray();
var message = Encoding.UTF8.GetString(body);
Console.WriteLine($" [x] Received {message}");
};
channel.BasicConsume(queue: "hello",
autoAck: false,
consumer: consumer);
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
```
4. Communication
L’envoi et la réception étant configurés, ne reste qu’à les faire communiquer ensemble !
Ouvrez 2 terminaux.
Vous pouvez lancez les clients dans n’importe quel ordre, les deux déclarant la même file d’attente.
Dans un souci de démonstration, exécutez cette commande dans le dossier Receive puis dans le dossier Send:
```CSharp
dotnet run
```
Le Worker va récupérer chaque message reçue du Sender via RabbitMQ.
Le Worker continuera a tourner indéfiniment, essayez de relancer le Sender plusieurs fois.
Scaling
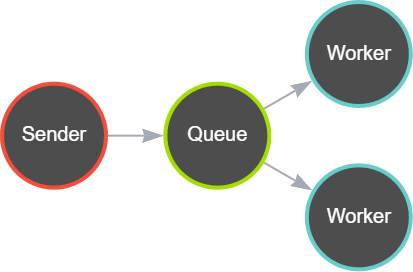
Parfois, il se peut que la tâche prenne du temps, que la file d’attente se remplisse et que vous vouliez accélerer le processus de traitement.
Nous ne pouvons pas accélerer le worker.
Cependant, nous pouvons répartir la charge sur plusieurs worker.
En effet, RabbitMQ réparti par défaut la charge sur plusieurs worker tant que le message délivré n’est pas acquitté par un worker.
Pour cela, nous n’aurons pas besoin de créer une autre file d’attente, avec un autre worker et un autre sender.
A la place, nous aurons seulement besoin de démarrer un autre worker, qui ira consommer la même file d’attente que notre premier worker.
Ainsi, les tâches en attentes mettront moins de temps à être traiter, la file d’attente distribuant la charge de travail dès qu’un worker se rend disponible.
Conclusion
Voici donc la conclusion de ce premier article, destiner à la prise en main du concept de RabbitMQ.
Différent de SignalR de par sa méthode de traitement, RabbitMQ reste un outil de messagerie très utile dans beaucoup de domaine, autant par sa facilité d’utilisation que sa gestion efficace des messages en cas de pannes.
Dans cette introduction nous avons vu comment utiliser RabbitMQ pour de la messagerie textuelle.
Plusieurs concepts ont été volontairement survolés ou oubliés, afin de ne pas rendre cette prise en main trop longue ni trop complexe.
Vous pourrez retrouver d’autres concepts sur le site de RabbitMQ
Pour finir voici une liste de liens externes pour aller plus loin :
- L’intégralité du code associé à cet article sur notre Github ;
- La formation de base à RabbitMQ dans la Documentation Officielle;
- Le point d’entrée vers la documentation complète de RabbitMQ
Je vous donne rendez-vous dans ce second article dédié à RabbitMQ et à son utilisation concrète !