
Avec la croissance continue d’Internet, les applications monolithiques historiques, se sont retrouvées dépasser par les exigences toujours plus fortes d’évolutivité des applications. Cette évolution technologique a propulsé les micro-services et la conteneurisation au premier plan des solutions d’architecture, offrant une manière interconnectée et efficace de relever les défis de mise à l’échelle et de gestion des applications, les rendant plus flexible.
De plus, l’avènement du cloud a accentué cette transition vers des infrastructures plus modulaires, ce qui conduit à l’émergence de technologies telles que Kubernetes, qui simplifie la gestion et l’orchestration de conteneurs et OpenShift, une plateforme qui exploite Kubernetes pour faciliter le déploiement et la gestion d’applications conteneurisées.
C’est quoi Kubernetes ?
Histoire
Pour la petite histoire : En 2014, Google développe un projet interne nommée Seven (en référence au personnage de Star Trek) basé sur Borg (un système d’administration de cluster) afin de créer une plateforme d’administration automatisé de déploiement, de mise à l’échelle et de gestion de conteneurs pour répondre à la demande exponentielle de leurs infrastructure et ainsi déployer des datacenters plus “simplement”. Par la suite, le projet fut repris par la CNCF (Cloud Native Computing Fondation). Aujourd’hui, Kubernetes en est à sa version 1.27.3 et est devenu un leader dans la gestion et l’orchestration de container à grande échelle.
Fonctionnement
Kubernetes est un outil DevOps IaC (Infrastructure as Code).
L’une des plus grosses utilités de Kubernetes est la gestion de charges, ce qui est extrêmement utile pour des applications à grande variation d’utilisateurs. Prenons comme exemple un service de streaming à grande échelle, il existe des périodes creuses ne nécessitant pas de grosse disponibilité de l’application (par exemple la journée), et au contraire il existe une période de forte affluence (le soir au moment du coucher).
Lors de cette forte affluence, il est indispensable que de nouvelles instances de l’application soient disponible. Pour cela, au lieu d’avoir des infrastructures à lancer manuellement une par une, la gestion de l’application est orchestrée par Kubernetes.
Tout d’abord, lors de la configuration de Kubernetes des workers lui sont attribués (qui sont pour la plupart hébergés dans le cloud).
Ensuite, on fournit à notre cluster les conteneurs utiles aux bons fonctionnements de notre application ainsi que la configuration voulu (exemple: 3 pods BDD, 1 Pods Back-end, 1 Pods Front-end). Une fois lancé, Kubernetes va pouvoir gérer automatiquement les différentes montées en charges de l’application en dupliquant simplement les Pods nécessaire sur les différents worker mis à disposition, et à contrario il peut supprimer les pods ( jusqu’à la limite définie) lors des périodes creuses ce qui permet de réduire l’utilisation des ressources (qui sont assez importantes quand on parle d’application qui peuvent utiliser des datacenters entier lors de forte affluence).
A haut niveau, Kubernetes est constitué de 2 types de nœuds (ensemble d’objets Kubernetes). Une partie Master et une partie Worker.
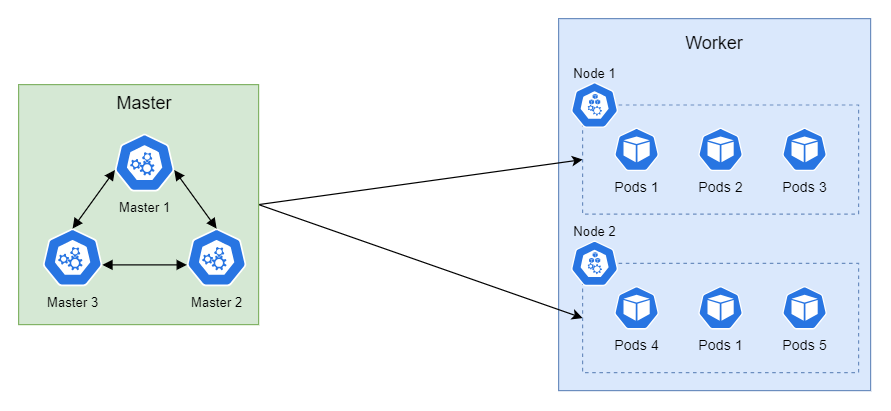
La partie Master, est le centre de commande (ou Control Plane) Kubernetes, c’est lui qui prend les décisions à propos du cluster et stocke les configurations des objets déployés. Il regroupe 3 processus :
- Le Scheduler (Planificateur) : Permet le déploiement des containers
- Load Balancer : répartiteur de charge
- API : Permet l’exécution de commande
Le nœud Master à la connaissance globale de ce qui se passe sur le cluster. Entre autres, il connait les ressources allouées aux nœuds “Worker” et les ressources qui y sont utilisées. Il peut donc choisir intelligemment sur quel worker déployer un nouveau container. Il gère tout seul l’emplacement des objets déployés à travers le cluster en fonction des prérequis de l’objet.
La partie Worker est celle où les conteneurs s’exécutent. Les conteneurs sont stockés dans des pods qui sont eux même gerés par des deployments qui sont dans des namespaces. Les droit sont gérés via des SCC attribuable par des service account … 🤯
Objets Kubernetes
Quelques objets les plus importants et les plus fréquents ainsi que leurs implémentations en YAML.
Container
Un conteneur contient une image d’un logiciel avec ses dépendances et l’exécute.
(Image : instance stockée d’un ensemble de programmes nécessaire à l’exécution d’une application)
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: myapp
image: <Image>
environement:
VAR: <value>
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: <Port>
Pod
La plus petite entité gérée par Kubernetes, qui contient un ou plusieurs conteneurs.
Il dispose d’un cycle de vie et de règles de réplication. Lors d’une montée de charge, c’est lui qui sera dupliqué pour répondre à la demande.
/* pods.yaml */
apiVersion: v1
kind: Pod
metadata:
name: myapp
labels:
name: myapp
spec:
containers:
...
SSC
Security Context Container (SCC) Définition des droits d’un conteneur. Lecture/écriture sur des dossiers et l’accès aux ressources. Il peut être nécessaire de modifier les SCC d’un pod, si ce dernier doit écrire des données dans un répertoire particulier, créer un dossier, etc. C’est souvent la source de nombreux problèmes de lancement de Pods.
apiVersion: v1
kind: Pod
metadata:
name: pod-scc
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: scc-container
securityContext:
allowPriviledgeEscalation: false
...
Service Account
Permet de fournir une identité aux différents éléments de Kube (pods et containers) ce qui permettra à ces éléments d’utiliser l’API de gestion du cluster.
apiVersion: v1
kind: ServiceAccount
metadata:
name: myserviceaccount
...
Service
Un service permet d’exposer des applications aux utilisateurs et aux autres composants du cluster. Il permet la répartition automatique de charge pour garantir une haute disponibilité et la résolution de nom de domaine interne (pour pouvoir communiquer entre pods sans utiliser l’adresse IP du pod).
apiVersion: v1
kind: Service
metadata:
name: myapp
spec:
selector:
app: myapp
ports:
- port: <Port>
targetPort: <Target Port>
Route (Ingress)
Permet d’exposer des services en dehors du cluster, elle définit une URL qui permet d’accéder à un service. Elles peuvent être configurées pour rediriger le trafic en fonction de nom d’hôte, du chemin URL, des headers HTTP ou d’autres critères.
/* Ingress Kubernetes */
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myingress
labels:
name: myingress
spec:
rules:
- host: <Host>
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: <Service>
port:
number: <Port>
/* Equivalent OpenShift (Route) */
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: myroute
spec:
to:
kind: Service
name: <Service>
port:
targetPort: <Port>
DaemonSet
Un daemonSet est un type de pod qui s’assure d’être déployé sur tous les nœuds du cluster. Il est notamment utilisé pour des tâches de monitoring et de surveillance.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: mydaemonset
spec:
selector:
matchLabels:
name: myapp
template:
metadata:
labels:
name: myapp
spec:
ConfigMap
Permet de stocker des données (non-confidentielles) dans des « clé – valeur ». Comme des fichiers yaml de configuration ou des variables d’environnement. Il est même possible d’ajouter le contenu d’un fichier.
/* configmap.yaml */
apiVersion: v1
kind: ConfigMap
metadata:
name: myapp
data:
key: value
config_file.json: |-
{
"property": "value"
}
PV et PVC
Persistent Volume et Persistent Volume Claim Le PV va définir un stockage persistent et le PVC est une demande de stockage persistent faite par une application. Kubernetes assure aux PVC d’allouer un PV correspondant aux exigences des PVC. Un PV peut avoir plusieurs PVC et non l’inverse.
/* pv.yaml */
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv
spec:
capacity:
storage: <Size>
volumeMode: Filesystem
persistentVolumeReclaimPolicy: Recycle
accessModes:
- ReadWriteOnce
/* pvc.yaml */
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
spec:
resources:
requests:
storage: <Size>
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
Namespace
Un namespace est un regroupement logique d’objets Kube (pods, PVC, daemonSet…). Les ressources d’un namespace ne peuvent pas communiquer ou faire référence à des ressources d’un autre namespace. Il n’y a pas de liaison inter-namespace (hors exception).
metadata:
namespace: myapp
Registry
Kubernetes intègre un registry qui permet de stocker et versionner des images Docker (c’est comme le Docker Hub). En général, on y pousse les images des applications du projet. Dans le cas d’un déploiement d’un container, l’image sera cherchée en premier dans le registry Kube, si elle n’est pas trouvée, l’image sera cherchée sur Internet.
Helm
Helm est le gestionnaire de package officiel de Kubernetes. Il permet via des Charts de définir, installer et mettre à jour des objets Kubernetes.
Helm utilise un format de packaging appelé charts. Un charts est une collection de fichiers qui décrivent un ensemble connexe de ressources Kubernetes.
Helm est composé de deux parties principales, les Template qui sont le corps de configuration et les Values qui sont des données de configuration qui peuvent être assimilées à des fichiers d’environnement, permettant de stocker les valeurs qui sont réutilisées dans la configuration. Il est possible de rajouter des conditions dans ces Templates (if, else, etc …) ce qui permet une grande adaptation.
Voici un exemple de fichiers Template et Values :
/* template.yaml */
apiVersion: apps/v1
kind: Pods
metadata:
name: {{.Values.name}}
namespace: {{.Values.namespace}}
labels:
app: {{.Values.name}}
spec:
selector:
matchLabels:
app: {{.Values.name}}
template:
metadata:
labels:
app: {{.Values.name}}
spec:
containers:
- name: {{.Values.name}}
image: {{.Values.repository}}
port:
- containerPorts: {{.Values.port}}
/* values.yaml */
name: my_app
namespace: my_porject
repository: nginx:latest
port: 3000
L’arborescence des fichiers :
my-chart
└─── Chart.yaml
└─── charts
└─── templates
| └─── deployment.yaml
| └─── configMap.yaml
└─── values.yaml
Le fichier Chart.yaml est le manifeste du Helm Chart. Il contient le nom du chart, sa description, ses dépendances, sa version et son icone.
Conclusion
Kubernetes est un excellent outil d’orchestration de conteneur, efficace et puissant. Il met à disposition un large choix de configuration et offre un confort d’infrastructure scalable.
Il est adapté à un environnement Cloud et convient essentiellement à des grosses applications. La grande majorité des Cloud Provider proposent des solutions basées sur Kubernetes : GKS pour Google Cloud Platform, EKS pour AWS, AKS pour Azure et OVH.
De plus, Kubernetes profite de surcouches comme OpenShift développé par RedHat
Pour évaluer vos connaissances acquises à travers cet article, nous vous proposons un petit test de connaissance interactif. Faire le test
Merci de votre attention et très bientôt pour un nouvel article !
Benjamin Fourmaux – Beruet && Baptiste Henry