
Présentation du projet
Ce projet qui nous a été confié a pour but la migration d’une application qui était hébergée sur des machines virtuelles vers une solution plus moderne : OpenShift.
OpenShift est une surcouche développée par RedHat, à l’outil d’orchestration de conteneur Kubernetes. On a d’ailleurs écrit un article pour vous présenter cette technologie.
Cette surcouche rajoute plusieurs fonctionnalités notamment en ce qui concerne la sécurité : Ajout de rôles (développeur, admin), Identification RBAC (Role Based Access Control), ajout d’une interface de gestion, support multi-cloud ainsi que des scans de sécurité des images Docker, et plein d’autres choses …
Au démarrage, notre maturité sur les technologies comme OpenShift et Kubernetes nous étaient encore faible. Nous avons donc approfondis nos connaissances en matière de DevOps et de l’IaC ainsi que sur le monitoring d’applications. Nous avons du en effet introduire des outils de récupération de logs et de métriques (Loki et Prometheus) ainsi qu’un outil de visualisation (Grafana).
Le projet est constitué de 3 briques applicatives (1 brique front et 2 briques back) ainsi que 2 bases de données (Redis et MongoDB). Des outils tel qu’une pipeline de CI a été mise en place pour build automatiquement des images de ces applications en image VM.
Déroulement du projet
Dans un premier temps, on a mis à jour la pipeline de CI pour qu’elle build les applications en image Docker, puis les envoyer sur un registry distant. Un registry permet de stocker des images Docker et de pouvoir les réutiliser.
Pour déployer nos objets sur le cluster, nous avons utilisé l’outil officiel de gestion de package de Kubernetes, HELM. Cet outil nous permet de créer des templates de déploiement et de configuration. L’utilisation du YAML et l’arborescence particulière des charts HELM peut se révéler un peu confusant au début.
En raison des contraintes techniques de l’environnement de développement et de prod (le cluster n’a pas accès à Internet), l’utilisation de templates préconstruit importés depuis ArtifactHub et Bitnami, fût une solution plus ou moins adéquate a notre projet. En effet les templates préconstruit sont souvent plus complexes que nécessaire ce qui n’aide pas à la compréhension.
Problèmes rencontrés
Lors de ce projet, nous avons eu à faire à de nombreux problèmes et notamment 2.
Le premier concerne les droits des pods, les SSC (Security Context Container). En effet certains pods ont besoin de droits supérieurs pour s’exécuter correctement, c’est notamment le cas des pods qui doivent communiquer avec d’autres pods et d’accéder à des ressources partagées.
Une façon simple de résoudre ce problème est d’utiliser les serviceAccount et les clusterRole afin d’attribuer des droits supplémentaires.
Le second fait référence à la taille limite d’un helm chart. Dans notre cas nous avions séparé en 2 Helm chart la partie applicative et la partie pour le monitoring. Sauf que cette dernière contenait trop d’outils et avait des chart trop volumineux. Rendant impossible la création du package.
Nous avons dû reséparé la partie monitoring en 2.
Monitoring d’un cluster
Dans le cadre d’une supervision opérationnelle il nous a fallu mettre en place des outils de monitoring. Ce système passe par la récupération des logs et des métriques ainsi que l’affichage dans des Dashboard.
Le monitoring permet aux équipes d’infra de pouvoir garder un œil sur le système global pour identifier les différentes pannes, erreur et dysfonctionnement.
Pour ce faire, nous utiliserons les outils suivants : Fluentd, Loki, Prometheus et Grafana.
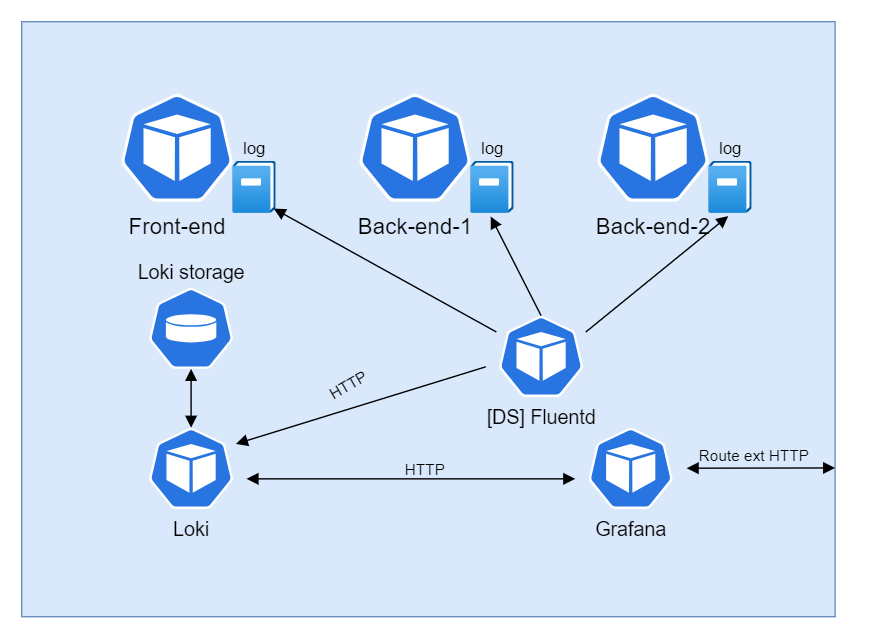
Dans un premier temps, nous devons récupérer les logs des applications, qui sont stockés dans un répertoire partagé au cluster (/var/log/pods/). Pour ce faire nous allons déployer un daemonSet de Fluentd sur le cluster.
Fluentd permet de faire 3 choses :
- La collecte des logs
- Le traitement des logs (pattern RegEx, changement de structure d’un log, formatage en json, format de la date …)
- Le transfert des logs pour le stockage vers un autre service
Nous avons donc paramétré Fluentd afin de récupérer ces fichiers de logs, puis de les convertir en JSON et de rajouter une propriété source, qui indique la provenance des logs (quelle application). Pour cette partie nous avons dû écrire 3 patterns regex afin de pouvoir capturer tous les formats de logs (format mono ligne et multi-lignes). On a trouvé un très bon site pour tester ces patterns Fluentular car Fluentd utilise sa propre écrire d’expression régulière. Puis pour finir, envoyer les logs traités vers Loki.
Voilà à quoi ressemble le fichier de configuration (fluent.conf) de Fluentd :
# Get Logs from app
<source>
@type tail
path "/var/log/pods/*/*-container/*.log" # Path to get Logs files
exclude_path ["/var/log/pods/openshift-*/*/*", "/var/log/pods/*_loki-*/*", "/var/log/pods/*_fluentd-*/*/*"]
pos_file "/fluentd/log/pods.log.pos"
tag container.*
read_from_head true
<parse>
@type none
</parse>
</source>
# Filter logs in JSON format
<filter container.**>
@type parser
key_name message
<parse>
@type multi_format
<pattern> # Log pattern
format regexp
expression "Fluentd regex"
time_key logtime
time_format %Y-%m-%dT%H:%M:%S.%N%z
</pattern>
</parse>
</filter>
# Ouput, send log to Loki
<match container.**>
@type copy
<store>
@type loki
url "http://loki_url/"
extra_labels {"env":"dev"}
flush_interval 10s
flush_at_shutdown true
buffer_chunk_limit 1m
</store>
</match>
Loki est un agrégateur de log, il va stocker les logs et exposer une API pour pouvoir envoyer et récupérer ses données. Il est possible de configurer Loki pour stocker les logs sur différents supports tel qu’un Persistent Volume, un serveur NFS ou encore un S3 Bucket.
Topologie du système de monitoring des logs
Pour le monitoring des métriques le projet utilise principalement Prometheus, de plus on utilise OpenTelemetry pour exporter les métriques des applications. En effet, il était nécessaire d’avoir une librairie dans les applications permettant d’exporter les métriques, car elles ne peuvent pas être récupérées directement par Prometheus.
Prometheus quant à lui collecte des métriques sur les performances et l’état des applications, les stocke dans une base de données temporelle et donne accès à des endpoint qui permets à des outils de dashboard comme Grafana de récupérer les données.
Dans le cas du projet, 3 utilitaires de prometheus sont utilisés :
-
kube state metrics : Il s’agit d’un composant qui collecte des métriques spécifiques de l’état des ressources Kubernetes/OpenShift, comme les déploiements, les pods, les services, etc. Il expose ces métriques au format Prometheus afin qu’elles puissent être collectées et utilisées pour surveiller l’état du cluster Kubernetes.
-
node-exporter : est un exporter pour les métriques spécifiques à la machine hôte (nœud) sur laquelle Prometheus est en cours d’exécution. Il collecte des métriques liées aux performances du système, telles que l’utilisation du processeur, la mémoire, le réseau … et les expose via des endpoints pour que Prometheus puisse les récupérer.
-
prometheus-operator : Le prometheus-operator simplifie l’administration de l’infrastructure de surveillance en décrivant la configuration à l’aide de ressources Kubernetes.
Pour profiter d’une pré-configuration de HELM et adapter à kubernetes nous avons utilisé kube-prometheus qui comporte les trois utilitaires décrit plutôt.
Après avoir collecter et stocker les logs et les métriques nous avons pu les afficher via un outil de dashboard : Grafana.
Grafana nous permet de définir des sources de données (Datasource) dans notre cas les données de Loki et Prometheus. Une fois les DataSource configurés il est possible de les affecter à des tableaux de bord pour permet une vue d’ensemble de ses données.
Dans ces dashboard, plusieurs types d’affichage sont disponibles : des jauges, des maps, des graphiques de toute sorte… De plus, il est possible de créer des règles d’alertes, qui par exemple prévienne les responsables infra d’une surconsommation de RAM par mail.
Conclusion
Ce projet nous a beaucoup apporté en compétences DevOps/IaC, sur le déploiement d’un cluster Kubernetes et sur le monitoring. Même avec 2-3 problèmes rencontrés, nous sommes arrivés au bout de ce projet et cela grâce à l’aide des très bonnes documentations des outils mise en place.
Merci de votre lecture et très bientôt pour un nouvel article !
Benjamin Fourmaux – Beruet && Baptiste Henry